This is an example of how to scrape Google News with the awesome rvest package.
This work is a solution for a question that appeared in our WhatsApp group, blackbeltR. A user came up with this problem and I decided to help him. It was a cool challenge, so why not?
A great deal of the basic ideas comes from his own code. I just kept it and added few things in order to get the code working.
First off, you should take a look at the Google News website HERE, which I reproduce below:
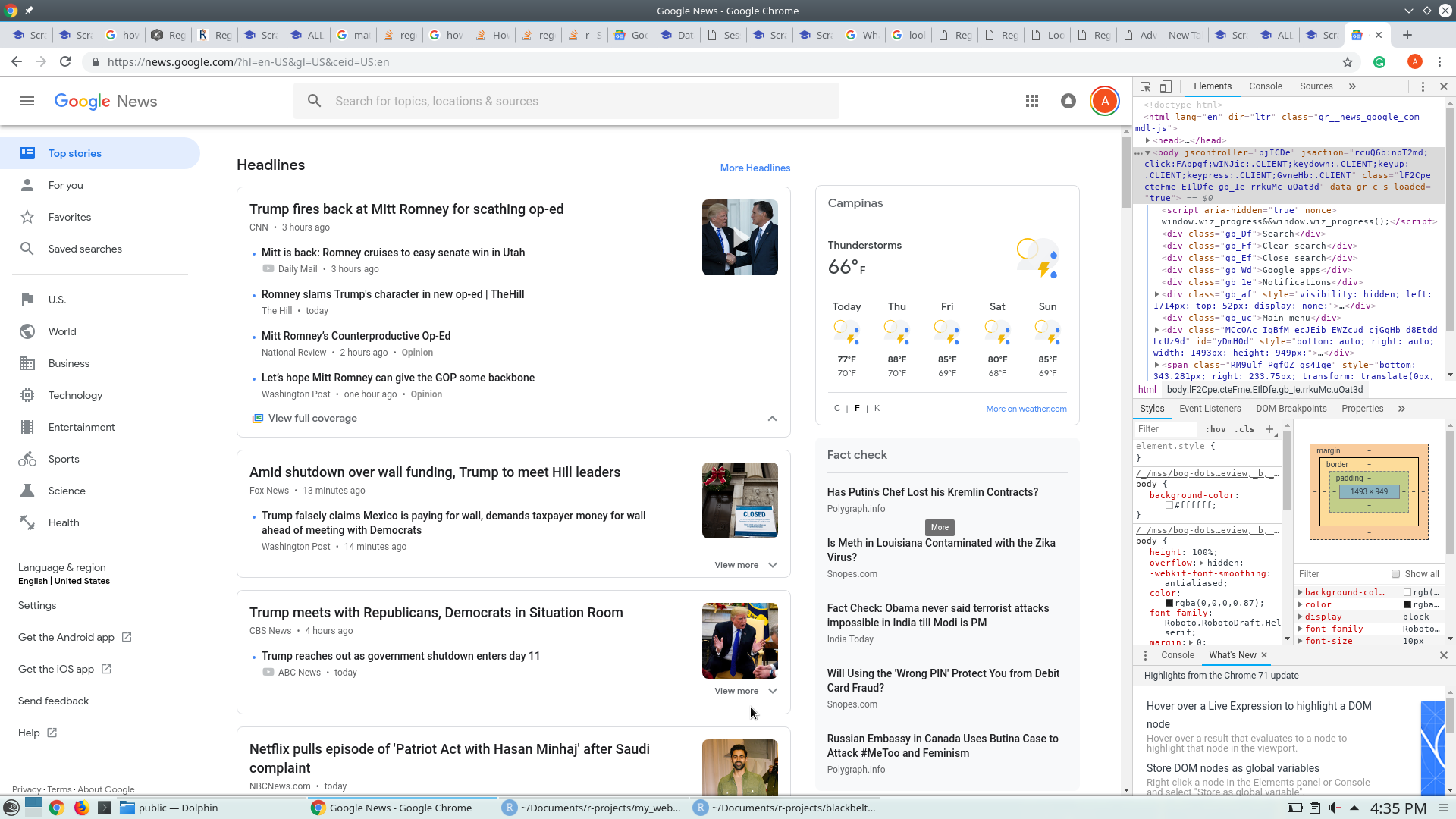
You may notice, on the right side of the page, that we are using Google Chrome dev-tools. We use this to identify the html nodes we need. You can access this tool by hitting the F12 key. The html nodes are passed as arguments to the rvest functions.
Basically, the idea is to extract the communication vehicle (vehicle), the time elapsed since the news was published (time), and the main headline (headline).
The code and coments are presented below:
[1] "CNN" "Fox News" "The Washington Post"
[4] "The New York Times" "Opinion" "Opinion"
[7] "Fox News" "Opinion" "Opinion"
[10] "HuffPost"
[1] "one hour ago" "one hour ago" "2 hours ago" "today"
[5] "today" "2 hours ago" "3 hours ago" "4 hours ago"
[9] "today" "one hour ago"
[1] "Pelosi says Democrats will give 'nothing for the wall'"
[2] "No deal to end shutdown; Trump says 'could be a long time'"
[3] "Trump falsely claims Mexico is paying for wall, demands taxpayer money for wall in meeting with Democrats"
[4] "Trump’s Shutdown Is Not About Border Security"
[5] "Doug Schoen: Democrats have Trump backed into a corner as 2019 kicks off"
[6] "Mitt Romney Pledges Support For Border Wall After Slamming Trump Administration"
[7] "Mitt Romney details what bothers him about Trumpvideo_youtube"
[8] "Trump fires back at Mitt Romney for scathing op-ed"
[9] "Mitt Romney’s Counterproductive Op-Ed"
[10] "Mitt Romney vs. Donald Trump: If Utah’s New Senator Is Serious, He Should Be Running for President" In this last case we used a regular expression (REGEX) to clean up the data. We did this by separating the actual headline phrases from the complementary ones. In some cases, we have a phrase ending with uppercase letters such as “NSA” (The National Security Agency) collapsed with other phrase initiating with another uppercase letter such as the article “A” (“…with NSAA agent said…”) for example. We have to think of a better way to split these cases, but the current result is quite satisfactory for now.
The expression ?<= is called “lookbehind”, while ?= is called “lookahead”. Those “lookaround” expressions allow us to look for patterns followed or preceded by something. In our case, the idea is to separate a string at the point in which lowercase letters, numbers, exclamation points, periods or question marks are collapsed with uppercase letters , e.g. where lowercase letters, numbers and others ([a-z0-9'!?\\.]) are followed (?<=) by uppercase letters or where uppercase letters ([A-Z]) are preceded (?=) by lowercase letters.
Before we finish, we have to clean up our data. It is common to collect garbage in the process such as data related to “fact checking”, which is a section on the right side of the page. As a result, it is possible that the three vectors we have created may have different sizes. Therefore, we use the smallest of them as the base and just delete the entries above this number on the other two vectors.
And we have our final data frame:
# A tibble: 158 x 3
vehicle_all time_all headline_all
<chr> <chr> <chr>
1 CNN one hour … Pelosi says Democrats will give 'nothi…
2 Fox News one hour … No deal to end shutdown; Trump says 'c…
3 The Washington… 2 hours a… Trump falsely claims Mexico is paying …
4 The New York T… today Trump’s Shutdown Is Not About Border S…
5 Opinion today Doug Schoen: Democrats have Trump back…
6 Opinion 2 hours a… Mitt Romney Pledges Support For Border…
7 Fox News 3 hours a… Mitt Romney details what bothers him a…
8 Opinion 4 hours a… Trump fires back at Mitt Romney for sc…
9 Opinion today Mitt Romney’s Counterproductive Op-Ed
10 HuffPost one hour … Mitt Romney vs. Donald Trump: If Utah’…
# ... with 148 more rows